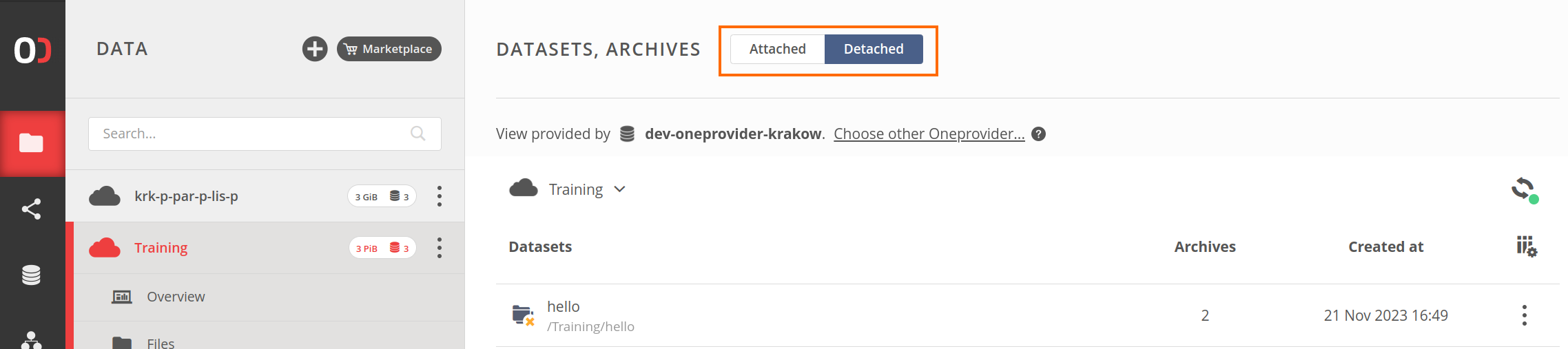
A note on the detached datasets
Datasets that are no longer needed (from the space data PoV) can be detached. A
detached dataset is decoupled from its root file/directory and serves only archival
purposes. All the archives created from the dataset are retained. The dataset does not
correspond to any physical content in the space file tree, but it shows up in the dataset
browser.
If the original file/directory is not deleted, the dataset can be later re-attached.
In the current version of Onedata, detached datasets can be viewed using the switch at the
top of the Datasets, Archives view.