# Datasets
# Overview
Datasets are essentially files or directories that have been marked by space users as representing data collections relevant to them. They can be used to organize data in a space systematically.
Datasets offer additional features, compared to regular files and directories:
- optional data and metadata write protection,
- dataset structure tracking using the dataset browser,
- ability to create persistent snapshots of the physical dataset contents — archives.
Datasets can be nested, allowing users to compose arbitrary hierarchical structures.

The diagram above shows the filesystem tree, where some directories are marked as datasets (Experiment A and Results). Regular files also can be marked as datasets (Statistics.csv). The file or directory is marked as a dataset by establishing the datasets on it.
# Establishing datasets
To establish a dataset, navigate to the file browser, open the context for a file or directory, and choose Datasets.
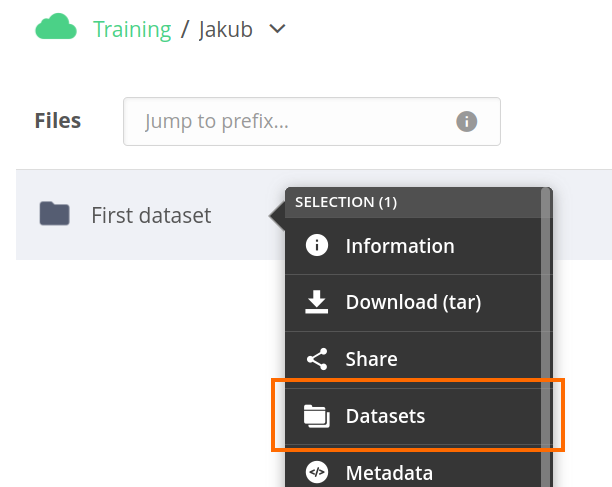
You will see a right-side dataset panel for the selected file or directory.
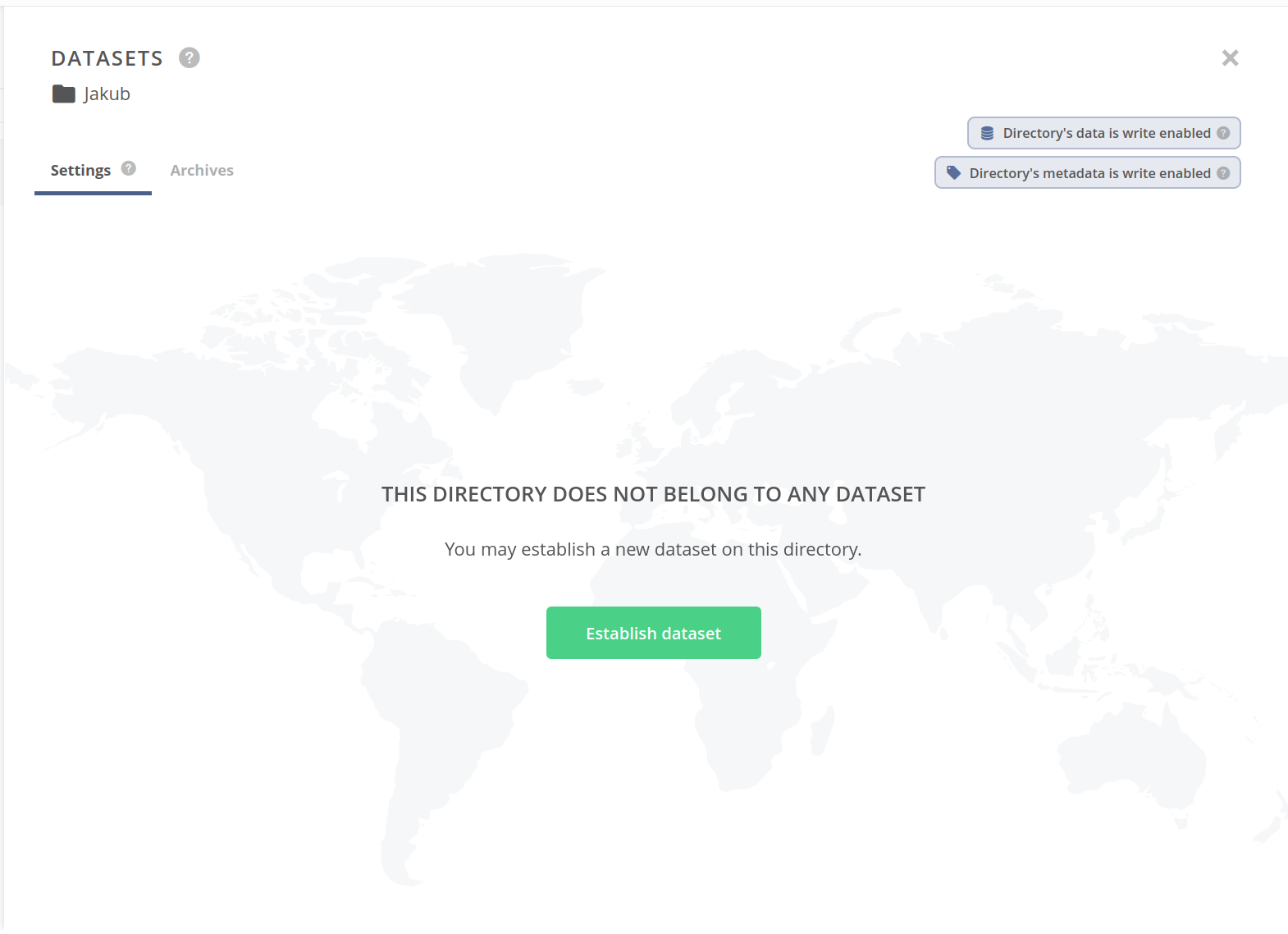
In this example, the selected directory has no dataset established. Click on the Establish dataset button in the center of the panel to create a dataset.
The panel should now present a summary of the dataset established on the selected directory.

# Datasets hierarchy
Datasets can be established on files or directories lying inside other datasets. This way, a hierarchy of datasets can be built and then embraced to create nested archives.
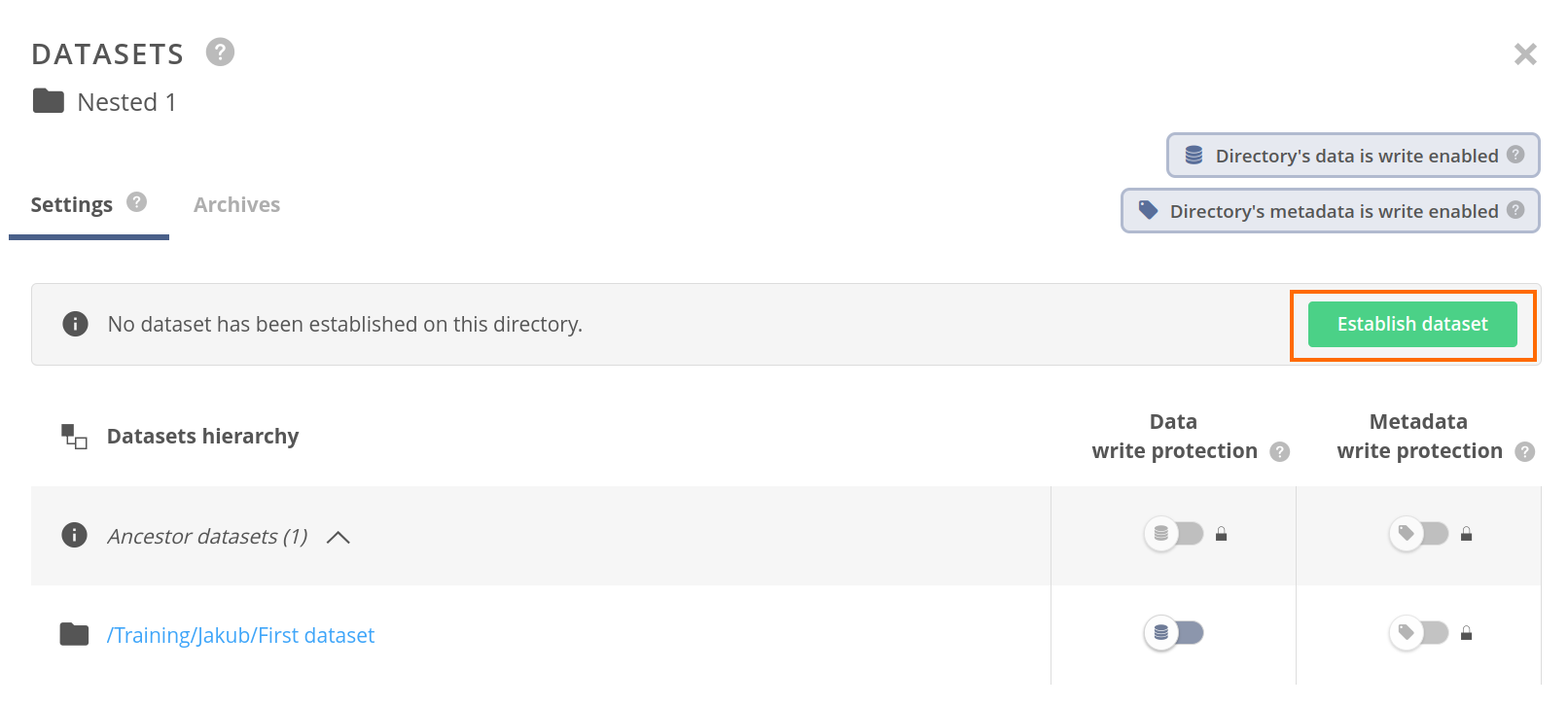
Navigate inside a directory with dataset established and open the Datasets panel for selected file or directory. The panel will show the existing hierarchy of the ancestor datasets. You can establish a nested dataset using the Establish dataset button placed above the ancestor table.
# File browser datasets panel
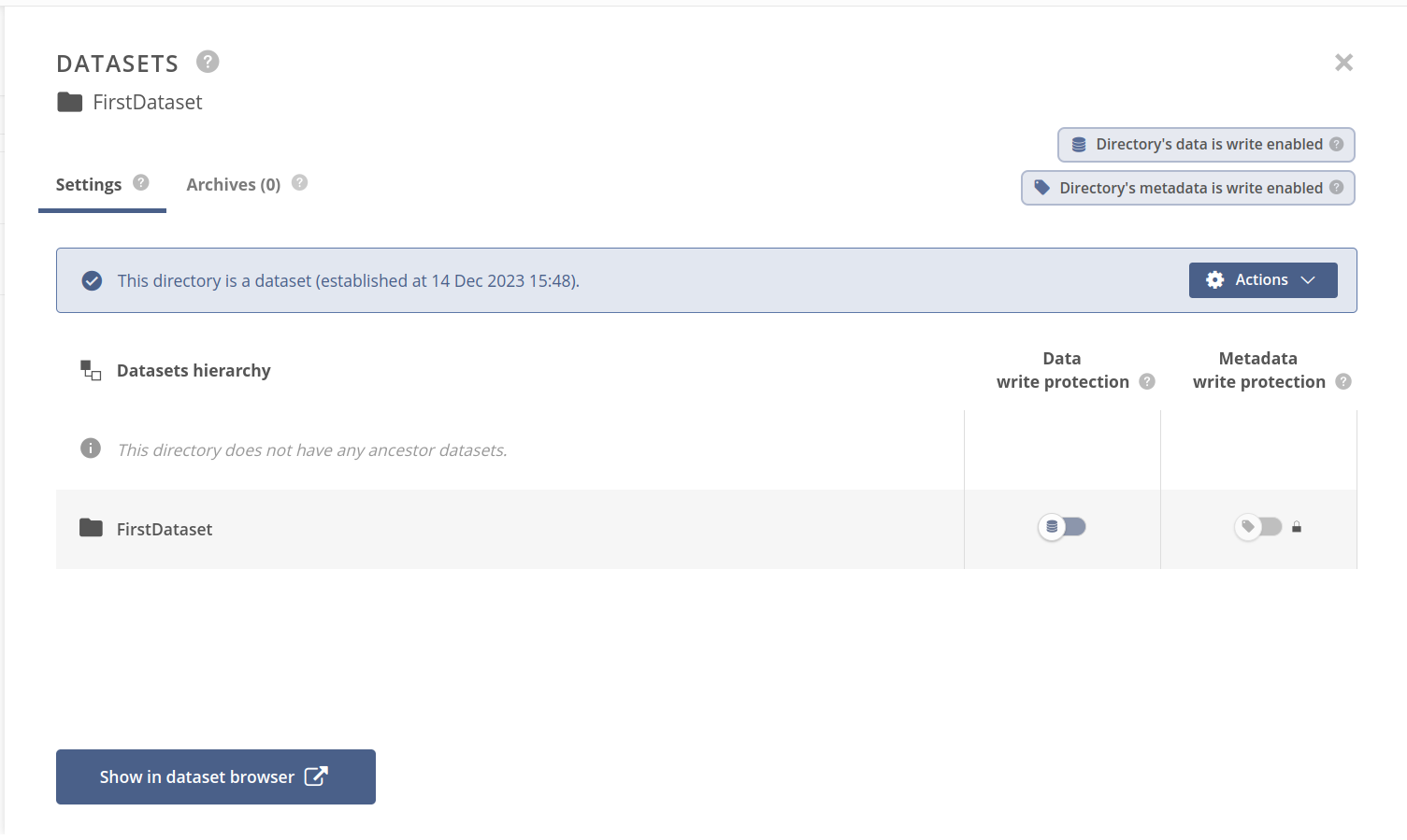
The Datasets panel for a file or directory presents information about the dataset established on the file/directory and its optional dataset ancestors. The view consists of:
- Settings tab — containing dataset status and actions, dataset hierarchy table with write protection configuration,
- Archives tab — containing dataset snapshots (archives) browser,
- write protection badges in the header — showing the effective write protection of the selected file or directory,
- Show in dataset browser button in the footer — navigating to Datasets, Archives tab within the space, with a focus on the selected dataset.
# Dataset actions
You can perform various actions on the established dataset:
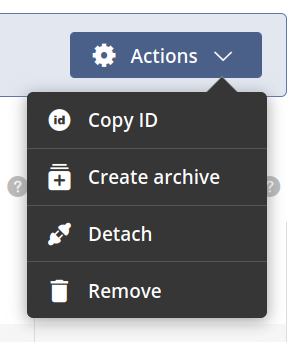
- Copy ID — copy the dataset ID into the clipboard,
- Create archive — create snapshot of the dataset (an archive),
- Detach — set dataset to detached state,
- Remove — remove the dataset feature from the file or directory.
If the dataset is already in the detached state, the Detach action becomes a Re-attach action which changes the dataset's state to attached.
# Dataset hierarchy table
The dataset hierarchy table shows a list of the ancestor directories having datasets established (and not detached). The first row of the table shows a summary of the ancestor datasets — you can click on it to show or hide the list. If there are any ancestors, the Data/Metadata write protection columns for the first row, show effective protection status inherited from the ancestors.
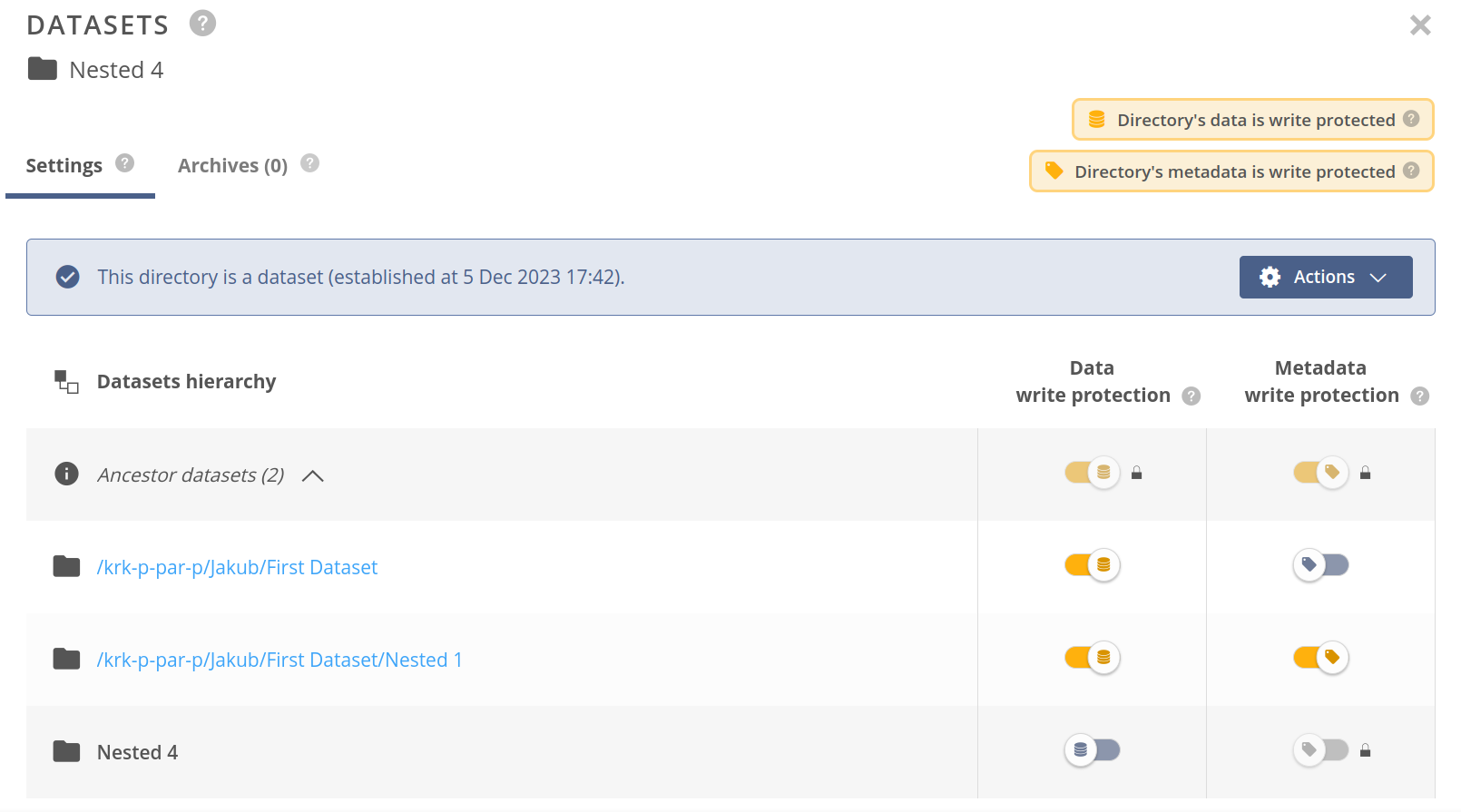
Rows for the ancestors contain links to the directories with datasets established and allow configuring the protection of each. The last row of the table shows information about the dataset established on the current file or directory and allows configuring the direct protection of this datasets.
NOTE
File's or directory's effective protection is presented using the badges at the upper-right side of the panel — it is a result of the ancestors and direct protection sum.
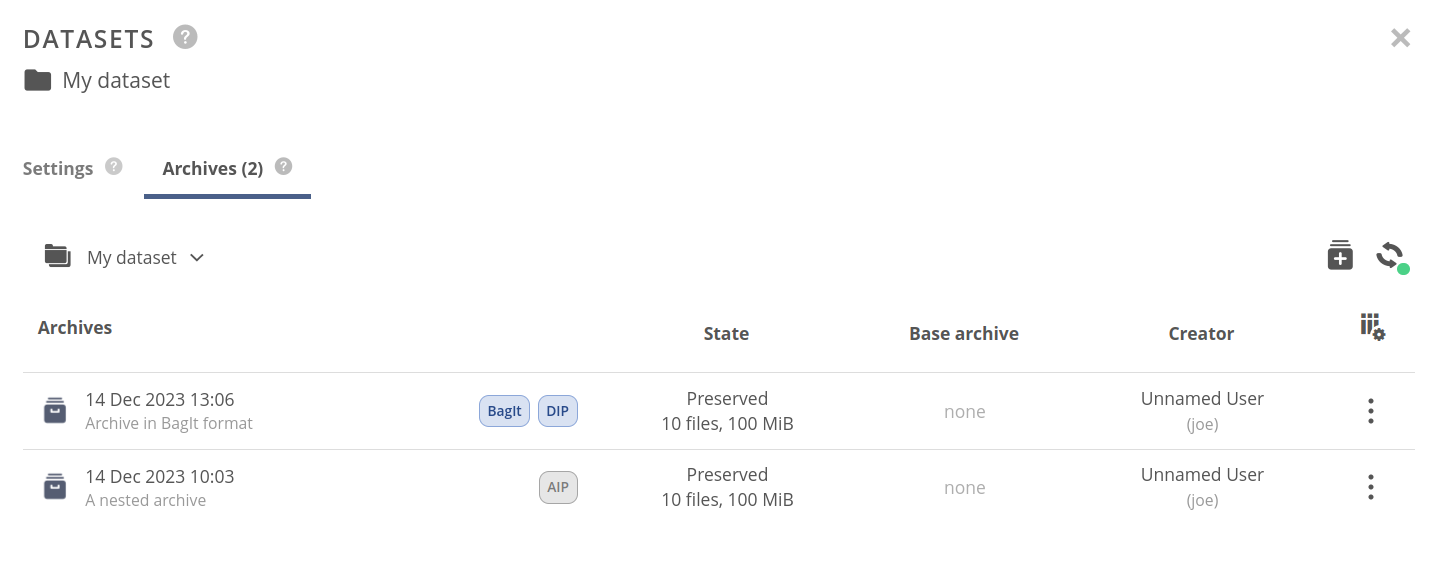
# Archives tab
The archives tab label displays the current number of snapshots created from the selected dataset. Inside the tab, you will find an archives list for the dataset — explained in detail in the archives' documentation.
# Data and metadata write protection
The lifecycle of a dataset can look like the following:
- acquisition — creating and collecting,
- consolidation and aggregation,
- processing/analysis,
- annotation,
- publishing/sharing,
- archiving.
Quite often, there is a need to apply certain procedures at different stages of data curation. For example, at the annotation stage, the dataset managers may wish to freeze its contents from further modifications. Similarly, at the publishing stage, the authors may wish to disable further changes to the annotated metadata — especially if the dataset has been assigned a persistent identifier and referenced in scientific works.
To prevent changes in the dataset, users can set temporary protection flags, which cause the files and directories in the dataset to be protected from, accordingly:
- Data protection — modifying their content or being deleted,
- Metadata protection — modifying their metadata, such as custom JSON/RDF/extended attributes metadata, permissions, or ACLs.
The protection flags are inherited by children datasets — datasets lower in the hierarchy tree have protection at least as strong as their ancestors.
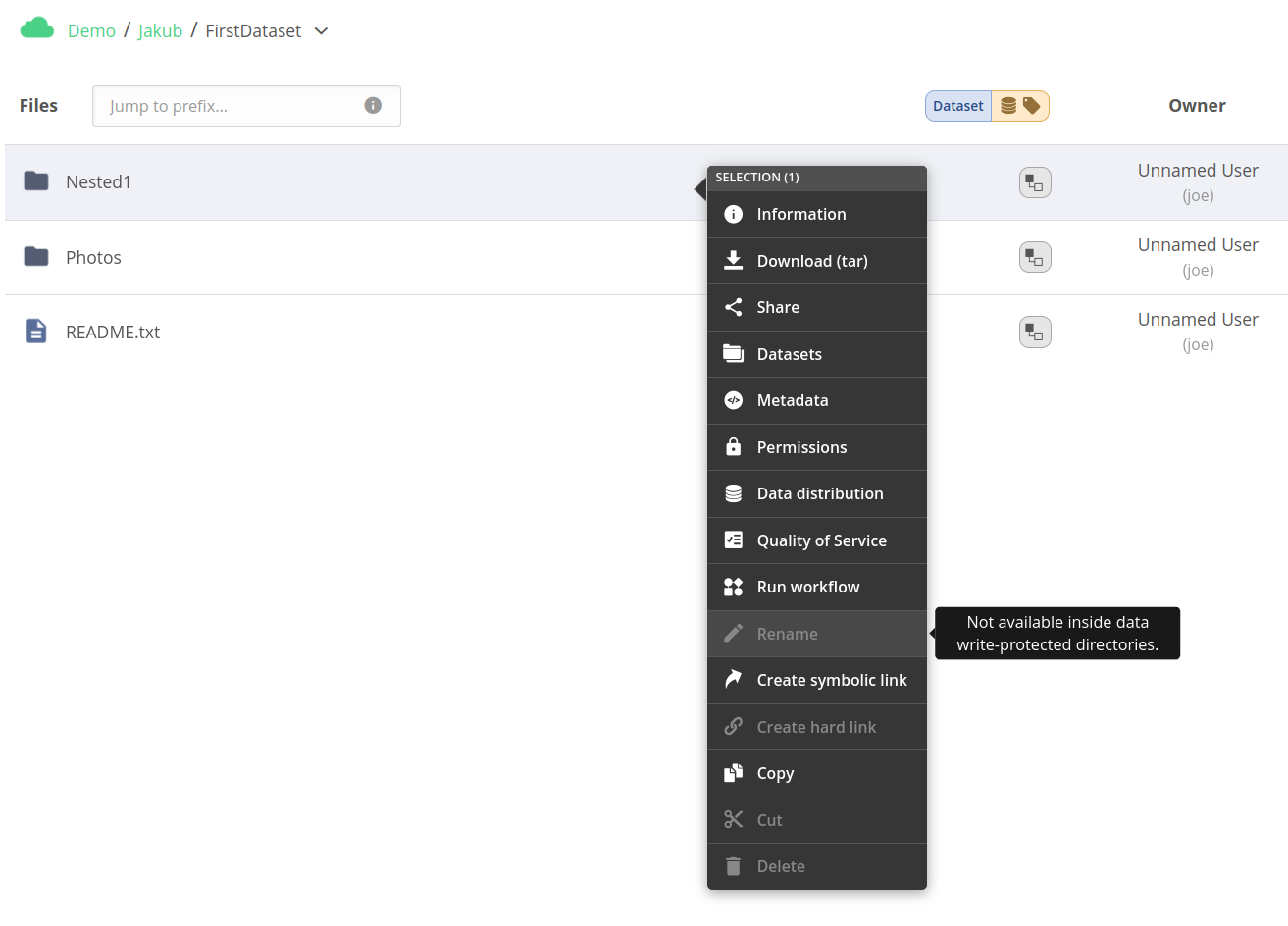
You can modify protection flags in the dataset hierarchy table of the file or directory datasets panel. When the file or directory has the protection enabled, the Datasets badge for the file has additional icons representing the applied protection.
The following screenshot presents data and metadata protection set on the FirstDataset directory, which makes impossible to rename files inside.
# Creating snapshots — archives
A snapshot of a dataset created at a certain point in time is called an archive.
Archives are immutable and stored within a space, lying in a special directory detached from the regular file tree. They can be accessed using the specialized browser of datasets and archives.
You can create archives using the Create archive action or in the archives tab of the file browser datasets panel.
See this chapter for more details.
# Detaching datasets
Datasets that are no longer needed (from the space data point of view) can be detached. A detached dataset is decoupled from its root file/directory and serves only archival purposes. All the archives created from the dataset are retained. The dataset does not correspond to any physical content in the space file tree, but it shows up in the dataset browser.
The dataset is also automatically detached when the corresponding file or directory is deleted.
If the original file/directory is not deleted, the dataset can be later re-attached. This can be done using the Re-attach action in the dataset actions.
# Removing datasets
Removing a dataset is essentially disabling the dataset-related features for a file or directory, leaving the data untouched, and causes the dataset to disappear from the dataset tree.
While detaching a dataset is not a harmful operation from the archive's perspective, deleting the entire dataset is, so the dataset cannot be removed until it has any archives.
For more information about deleting archives, refer to this page.
You can remove a dataset without an archive, using the Remove action in the dataset actions.